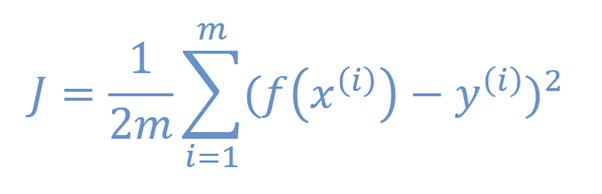Cost Functions
Regression is fallible.
When we fit lines to data, we can make mistakes. And like most mistakes, they can carry a cost.
Which begs the question: how much of a cost?
To find out, we use cost functions. They output a number, and the higher the number, the worse the error.
So, by finding the point where our cost function is smallest, we find the best line/curve to draw over our data.
But this is easier said than done.
Which brings us to gradient descent.
---
For those interested, for a training dataset of m datapoints, where the ith datapoint is (x(i), y(i)) and our trendline has function f(x), the cost function J is: