Neural Networks
Forget everything you know about neurons.
Instead of soma and axons, these digital “neurons” are mini linear regression models.
The only difference compared to the linear regression we’ve already covered?
The output of these models is passed through another function (called an “activation function”) to produce the final output of each neuron.
The network is arranged as follows:
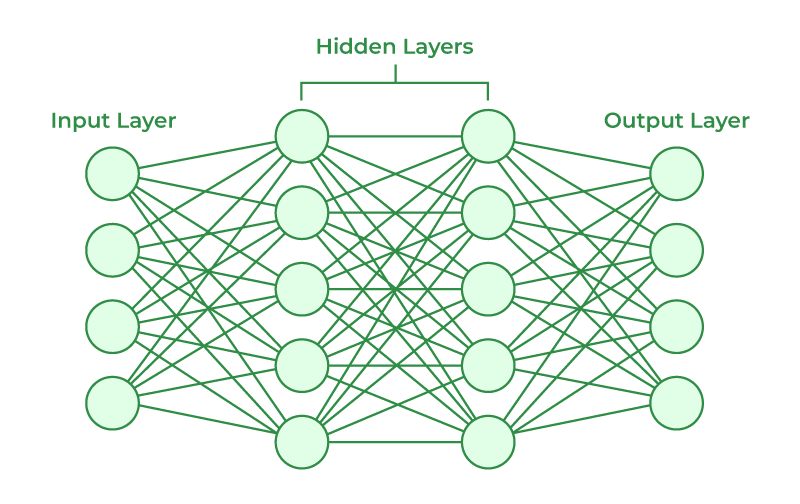
Data flows from left to right, and each neuron is connected to all other neurons in the adjacent layers.
Here, our weights determine the strength of the connection between any two neurons, and the biases add a discrete value to each neuron’s output before it’s passed through the activation function.
And so, given an input, neurons compute their values, pass them to one another based on the strengths of their connections, and produce a set of neuron values in the output layer.
Don’t be intimidated.
If you understand linear regression, you understand this.
The only difference is that we’re connecting lots of linear regression models together and running their outputs through another function, giving us an extra layer of complexity (and thus more powerful pattern recognition).
It's simpler than it looks (at least, for our purposes).
Last but not least, let’s discuss backpropagation.